AIDA – Performance Testing
![]()
![]()
![]()
AIDA64 contains several tests that can be used to evaluate the performance of individual pieces of equipment or the system as a whole. These are synthetic tests, meaning they can evaluate the theoretical maximum performance of a system. Memory, CPU, or FPU throughput tests are based on the AIDA64 multithreaded test engine, which supports up to 640 concurrent processing threads and 10 processor groups (starting with AIDA64 Business 4.00). This mechanism provides full support for multiprocessors (SMP), multi-core and hyperthreading technologies.
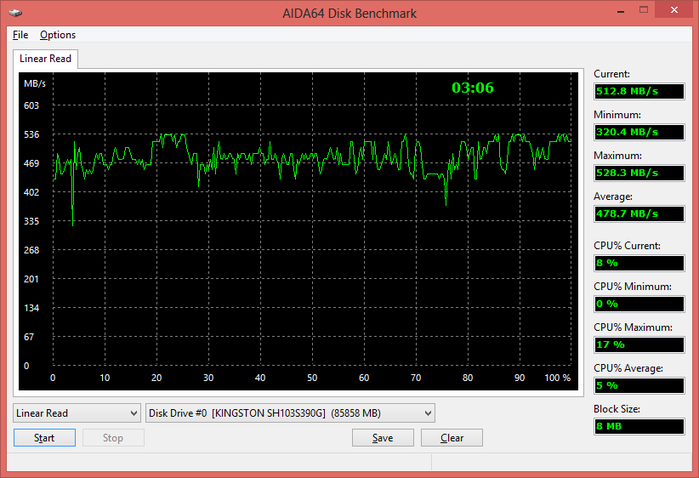
Cache and Disk Performance Testing
AIDA64 also offers separate tests to assess read, write and copy bandwidth, as well as processor cache and system memory latency. There is also a separate test module for evaluating the performance of storage devices, including (S)ATA or SCSI hard drives, RAID arrays, optical drives, SSDs, USB drives and memory cards.
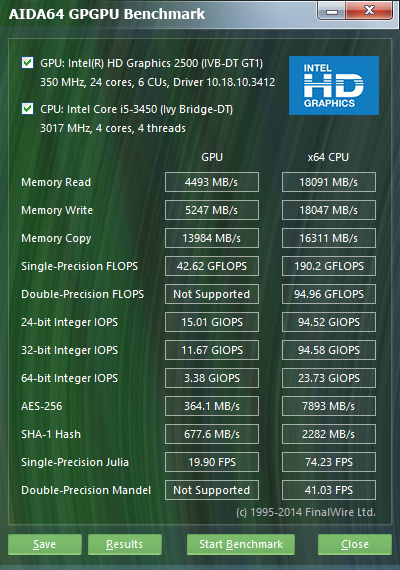
GPGPU Performance Testing
This is a test pane that can be accessed from the Tools menu section | GpGPU test, offers a set of OpenCL GPGPU performance tests. They are designed to evaluate gpgPU computing performance using a variety of OpenCL workloads. Each individual test can be performed on a maximum of 16 GPUs, including AMD, Intel, and NVIDIA processors, or a combination of both. Of course, CrossFire and SLI configurations, as well as dGPU and APU, are fully supported. In general, this feature allows you to test the performance of almost any computing device that is represented as a graphics processor among OpenCL devices.
In addition to comprehensive performance tests, AIDA64 offers special microtests – they can be found in the “Tests” section of the “Page” menu. Thanks to a comprehensive reference database of results, the results of performance tests can be compared with similar indicators for other configurations. The following microtests are currently available:
Memory Performance Testing
Memory performance tests evaluate the maximum possible throughput when performing certain operations (read, write, copy). They are written in assembly language and are optimized as much as possible for all popular variants of AMD, Intel and VIA processor cores by applying the appropriate x86/x64, x87, MMX, MMX+, 3DNow!, SSE, SSE2, SSE4.1, AVX and AVX2 instruction set extensions.
The memory latency test evaluates the typical latency when the CPU reads data from system memory. Memory latency is the time to provide data in the CPU integer arithmetic register after the read command is issued.
CPU Queen
This simple integer test evaluates the ability to predict CPU branches and erroneously predict branches. He calculates solutions for a classic puzzle with eight queens placed on a 10×10 chessboard. Theoretically, at the same clock speed, a processor with a shorter pipeline and less overhead in the case of an erroneous assumption about branching can show higher test results. For example, if you turn off hyperthreading, Pentium 4 processors based on Intel Northwood will get higher scores than Intel Prescott CPUs, since the former have a 20-speed pipeline, and the latter have a 31-speed pipeline. CPU Queen uses integer optimizations MMX, SSE2 and SSSE3.
CPU PhotoWorxx
This integer test evaluates the performance of the CPU using several algorithms for processing two-dimensional photos. It performs the following tasks with fairly large RGB images:
- Filling the image with pixels of a randomly selected color;
- rotate the image 90 degrees counterclockwise;
- rotate the image 180 degrees;
- image differentiation;
- Color space conversion (used, for example, in JPEG conversion).
The test is mainly intended for blocks performing integer arithmetic operations of the SIMD architecture of the CPU and memory subsystems. The PhotoWorxx CPU test uses the appropriate x87, MMX, MMX+, 3DNow!, 3DNow!+, SSE, SSE2, SSSE3, SSE4.1, SSE4A, AVX, AVX2 instruction set extensions, and supports NUMA, hyperthreading, multiprocessors (SMP), and multi-core (CMP).
CPU ZLib
This integer test evaluates the combined performance of the CPU and memory subsystem using the free ZLib data compression library. The ZLib CPU uses only x86 basic instructions, but supports hyperthreading, multiprocessors (SMP), and multi-core (CMP).
CPU AES
This integer test evaluates the performance of the CPU when performing encryption using the AES cryptographic algorithm. In encryption, AES is a symmetric block encryption algorithm. Today, AES is used in several compression tools, such as 7z, RAR, WinZip, as well as in BitLocker encryption programs, FileVault (Mac OS X), TrueCrypt. Cpu AES uses the corresponding x86, MMX and SSE4.1 instructions, it is hardware accelerated on VIA C3, VIA C7, VIA Nano and VIA QuadCore processors that support VIA PadLock Security Engine technology, as well as on processors that support the expansion of Intel AES-NI instruction sets. This test supports hyperthreading, multiprocessors (SMP), and multi-core (CMP).
CPU Hash
This integer test evaluates the performance of the CPU when executing the SHA1 caching algorithm according to Federal Information Processing Standard 180-4. The code for this test is written in assembly language and is optimized for most popular AMD, Intel, and VIA processor cores by applying the appropriate mmx, MMX+/SSE, SSE2, SSSE3, AVX, AVX2, XOP, BMI, and BMI2 instruction set extensions. The CPU Hash test is hardware accelerated on VIA C7, VIA Nano and VIA QuadCore processors that support VIA PadLock Security Engine technology.
FPU VP8
This test measures the video compression performance of the Google VP8 (WebM) codec version 1.1.0. Encodes for 1 pass of the video stream with a resolution of 1280×720 (“HD ready”) and a speed of 8192 kbit/s at maximum quality settings. The contents of the frames are generated by the Julia FPU fractal module. The test code uses MMX, SSE2, SSSE3, or SSE4.1 extensions and instruction sets, and supports hyperthreading, multiprocessors (SMP), and multi-core (CMP).
FPU Julia
This test evaluates performance in single-precision floating-point operations (32-bit precision) by calculating multiple fragments of Julia’s fractal. The code for this test is written in assembly language and is optimized for most popular AMD, Intel, and VIA processor cores by applying the appropriate x87, 3DNow!, 3DNow!+, SSE, AVX, AVX2, FMA, and FMA4 instruction set extensions. The Julia FPU supports hyperthreading, multiprocessors (SMP), and multi-core (CMP).
FPU Mandel
This test evaluates performance in double-precision floating-point operations (64-bit accuracy) by simulating multiple fragments of mandelbrot fractal. The code for this test is written in assembly language and is optimized for most popular amd, Intel, and VIA processor cores by applying the appropriate x87, SSE2, AVX, AVX2, FMA, and FMA4 instruction set extensions. Mandel’s FPU supports hyperthreading, multiprocessors (SMPs), and multi-core (CMP).
FPU SinJulia
The test evaluates performance in high-precision floating-point operations (80-bit accuracy) by calculating on a single frame using a modified Julian fractal. The code for this test is written in assembly language, it is optimized for most popular variants of amd, Intel and VIA processor cores, allows you to use trigonometric and exponential instructions of the x87 architecture. SinJulia FPU supports hyperthreading, multiprocessors (SMPs), and multi-core (CMP).
This feature is supported in the following versions:
| Aida64 Business | |
| Aida64 Engineer | |
| Aida64 Extreme for Home |